tl;dr
I tasked Claude, Codex, and Gemini to build a SQLite-like engine in Rust.
- ~19k lines of code.
- Parser, planner, volcano executor, pager, b+trees, wal, recovery, joins, aggregates, indexing, transaction semantics, grouped aggregates, and stats-aware planning all implemented.
- 282 passing ai-written unit tests (this project certainly fails against the official sqlite test suite, so I did not bother testing).
response to hacker news post
does it actually work?
Yes, for a supported subset of SQL. To establish a baseline, I integrated the SQLLogicTest suite.
- Pass Rate: The engine passes 64 queries (including core CRUD, JOINs, and GROUP BY).
- Failures: Most failures in the 1,000+ query
select1.sltsuite are due to unsupported syntax (Subqueries,CASE,EXISTS).code quality
There are several slop patterns in the codebase:
- Freelist linear search: The agents initially implemented a linear scan of the freelist to check for duplicates.
- Buffer Clones: The pager was performing redundant
.clone()calls on large page buffers during WAL flushes.- Concurrency: There is currently no concurrency.
is this “sqlite”?
No. It is a “simulacrum” of SQLite’s architecture. It is an experiment in agent orchestration, not a production database.
background
Treat software engineering like distributed systems, and force coordination with: git, lock files, tests, and merge discipline.
harness
├── AGENT_PROMPT.md // main agent task prompt
├── BOOTSTRAP_PROMPT.md // bootstrap (initialization) prompt
├── COALESCE_PROMPT.md // deduplication prompt for coalescer agent
├── launch_agents.sh // launches all agents and sets up isolated workspaces
├── agent_loop.sh // per-agent loop/worker script
├── restart_agents.sh // restarts agents
└── coalesce.sh // invokes the coalescing script
workflow
- bootstrap phase: one Claude run generates baseline docs, crate skeleton, and test harness.
├── Cargo.toml // crate manifest ├── DESIGN.md // architecture design notes ├── PROGRESS.md // test & build progress ├── README.md // project overview ├── agent_logs // per-agent log files ├── crates // workspace subcrates ├── current_tasks // lock files ├── notes // inter-agent notes ├── target // build artifacts └── test.sh // test harness script - worker phase: six workers loop forever (
2x Claude,2x Codex,2x Gemini).- The choice of two workers per model is purely pragmatic: I can’t afford more.
- I chose heterogeneous agents because it has not been done yet. There is no performance justification for this choice.
loop
- Each agent pulls latest main.
- Claims one scoped task.
- Implements + tests against sqlite3 as oracle.
- Updates shared progress/notes.
- Push.
analysis
coordination tax
- 84 / 154 commits (54.5%) were lock/claim/stale-lock/release coordination.
- Demonstrates parallel-agent throughput depends heavily on lock hygiene and stale-lock cleanup discipline.
what helped most
Two things looked decisive:
- oracle-style validation + high test cadence (
cargo test ...and./test.sh --fast/full runs captured inPROGRESS.md). - strong module boundaries (
parser -> planner -> executor <-> storage) so agents could work on orthogonal slices with fewer merge collisions.
redundancy
I implemented a coalescer with gemini to clean duplication/drift, since that is the largest problem with parallel agents. However, it only ran once at the end of the project, so it was never actually used during the run itself. I have a cron job which runs it daily, but gemini couldn’t complete the entire de-deuplication when I ran it during the expirement itself, which is to say it stopped mid-way through.
takeaways
- Parallelism is great, but only with strict task boundaries.
- Shared state docs (PROGRESS.md, design notes) are part of the runtime, not “documentation.”
- Tests are the anti-entropy force.
- Give agents a narrow interface, a common truth source, and fast feedback, and you get compounding throughput on real systems code.
replication
To replicate this setup:
git clone git@github.com:kiankyars/parallel-ralph.git
mv parallel-ralph/sqlite .
chmod 700 sqlite/*.sh
./sqlite/launch_agents.sh
restart agents:
./sqlite/restart_agents.sh claude/codex/gemini
coalesce agent:
./sqlite/coalesce.sh
Assumes you have the relevant CLIs installed (claude, codex, gemini), plus screen, git, Rust toolchain, and sqlite3.
limitations
- The documentation in the repo became enormous,
PROGRESS.mdbecame 490 lines and look at the sheer amount of notes; all this to say that the coalesce agent must be run as often as the other agents. - There isn’t a great way to record token usage with cli coding agents (as opposed to API use which is trivial), so I don’t have a grasp on which agent pulled the most weight.
future work
- Track “substantive run rate”, since many are rate-limited/nothing happened.
- Only Claude adds itself as a co-author to each commit and I did not do that for Codex and Gemini, so I need to add a commit message for Gemini and Codex.
- Adding more strict observability because probably a lot of errors were due to rate-limiting.
inspiration
appendix
code size snapshot
| Language | Files | Lines | Non-blank/Non-comment |
|---|---|---|---|
| Rust | 14 | 18,650 | ~16,155 |
| Shell | 1 | 199 | ~139 |
| Total | 15 | 18,849 | ~16,294 |
154 commits between 2026-02-10 and 2026-02-12.
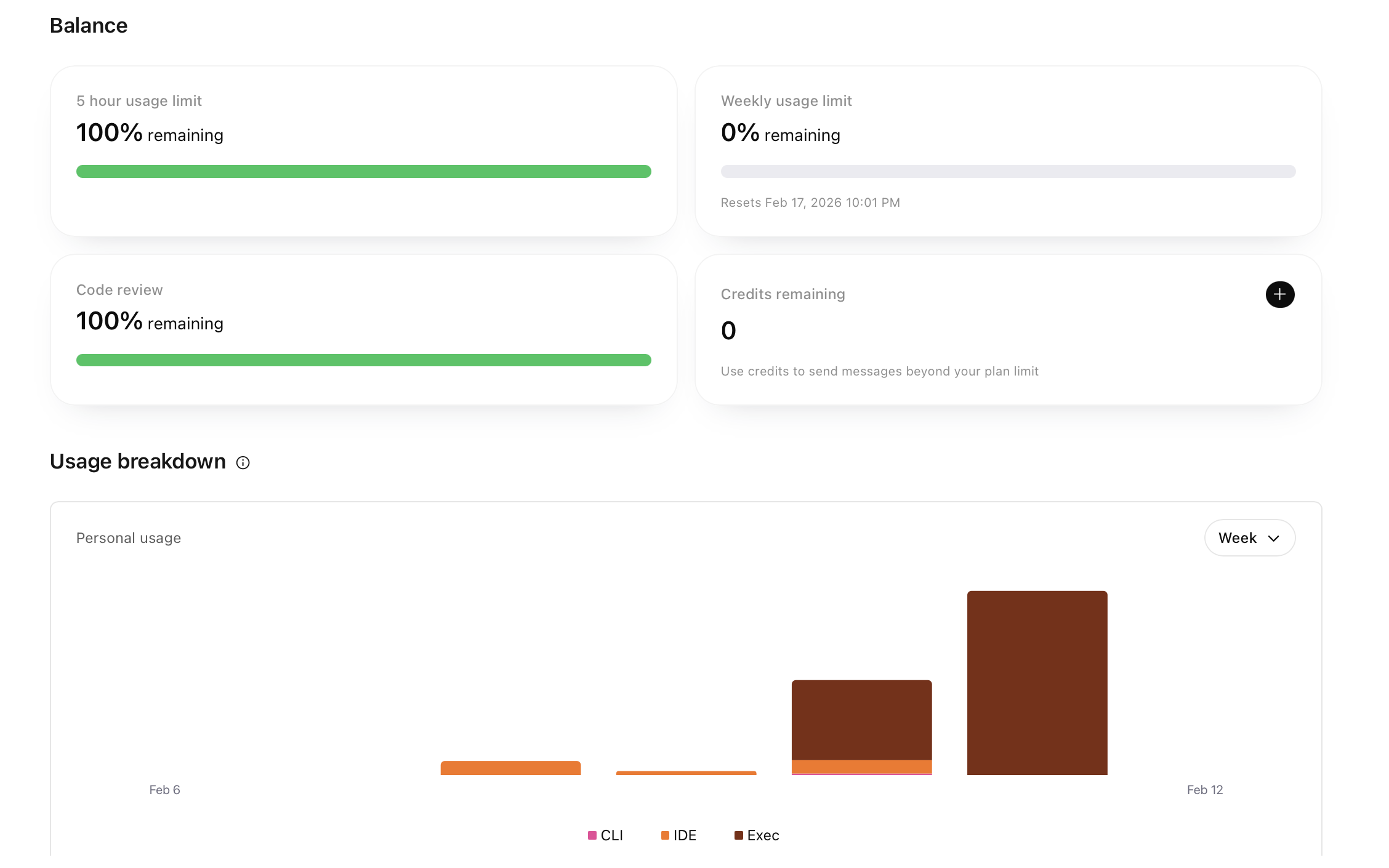
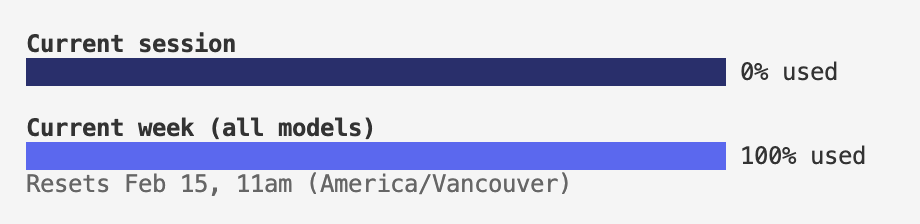
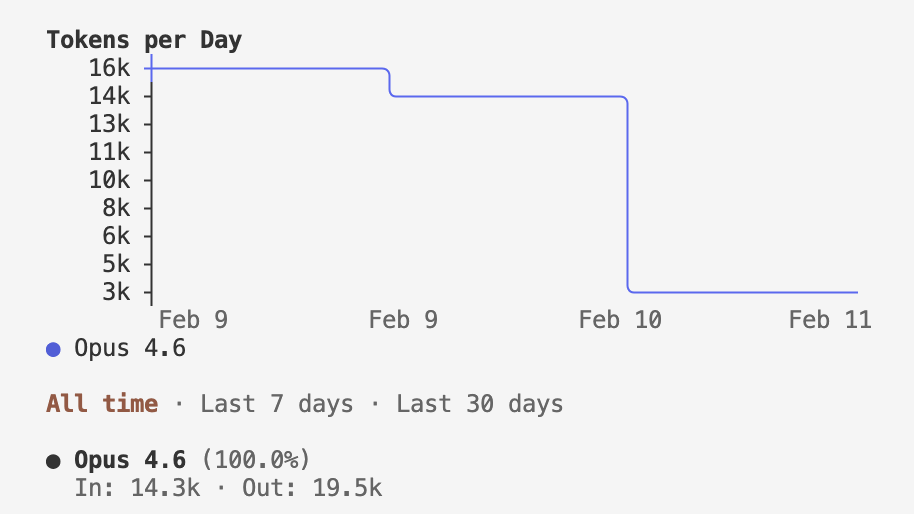
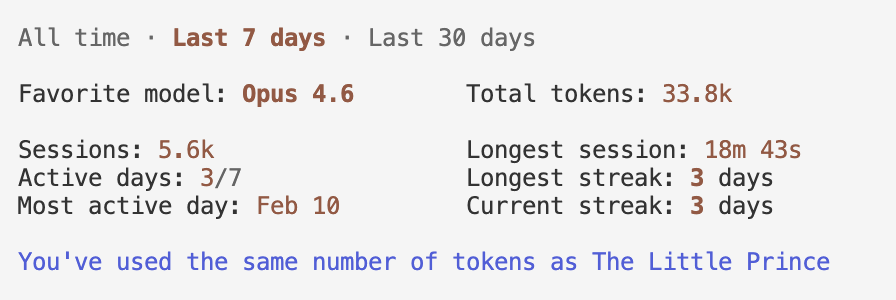
usage
Gemini does not offer a way to monitor usage with their CLI. It’s also not on a weekly usage basis, but rather a 24-hour usage basis. For codex, I used 100% of the Pro Plan weekly usage, which is currently on a 2x promotion. I used 70% of the Claude Pro weekly usage.
- codex
- claude
disclaimer
- codex wrote the first draft for this post.
citation
@misc{kyars2026sqlite,
author = {Kian Kyars},
title = {building sqlite with a small swarm},
year = {2026},
month = feb,
day = {12},
howpublished = {\url{https://kiankyars.github.io/machine_learning/2026/02/16/sqlite.html}},
note = {Blog post}
}