microddp
Introduction to Distributed Data Parallelism
Why Distributed Training?
Training large models on a single GPU faces three challenges:
- Model too large: May not fit in GPU memory.
- Batch size: OOM errors.
- Time: Can take years on huge datasets.
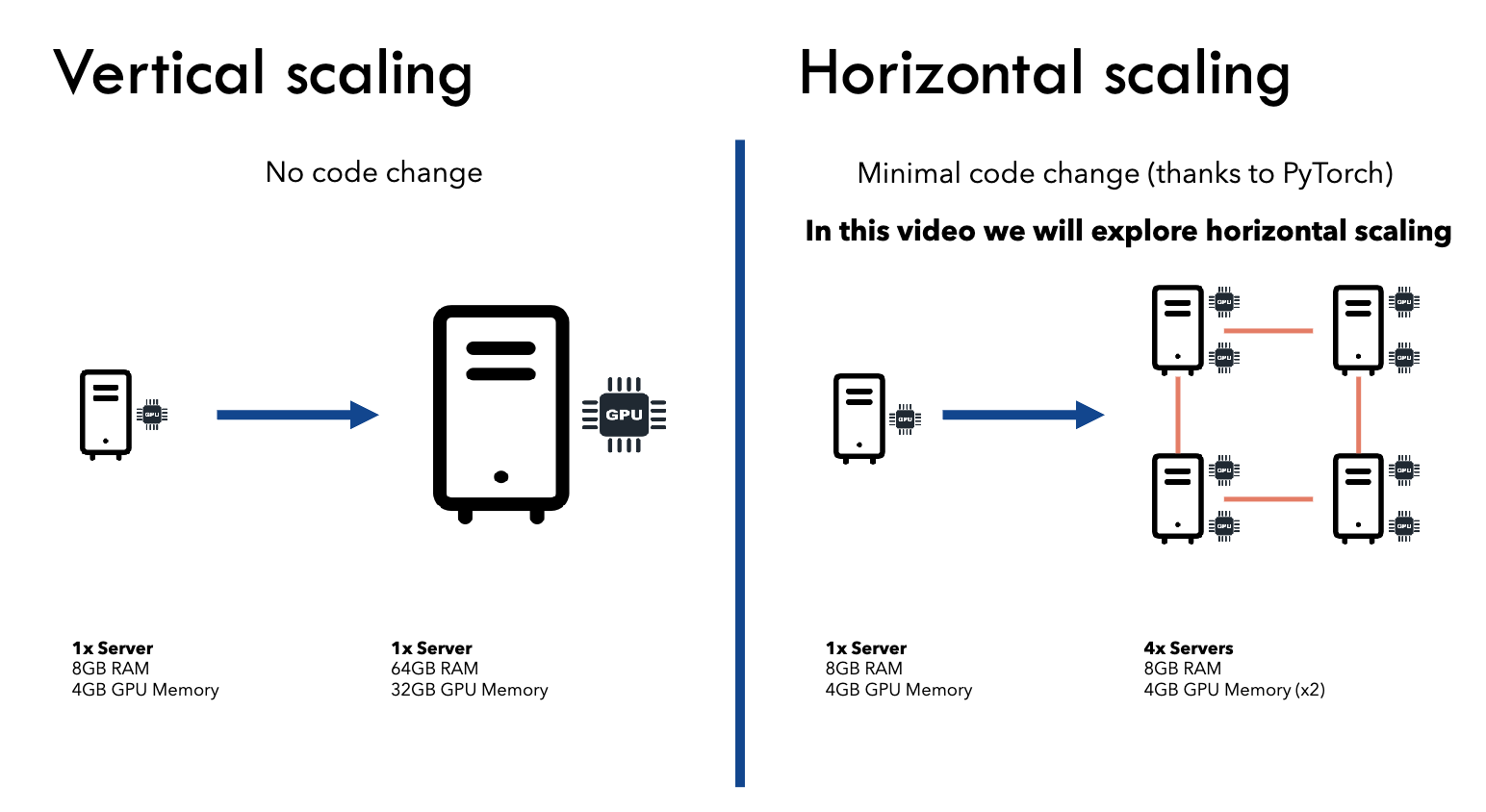
- Scale horizontally (multiple GPUs/servers) or vertically (bigger GPU).
Data Parallel vs Model Parallel
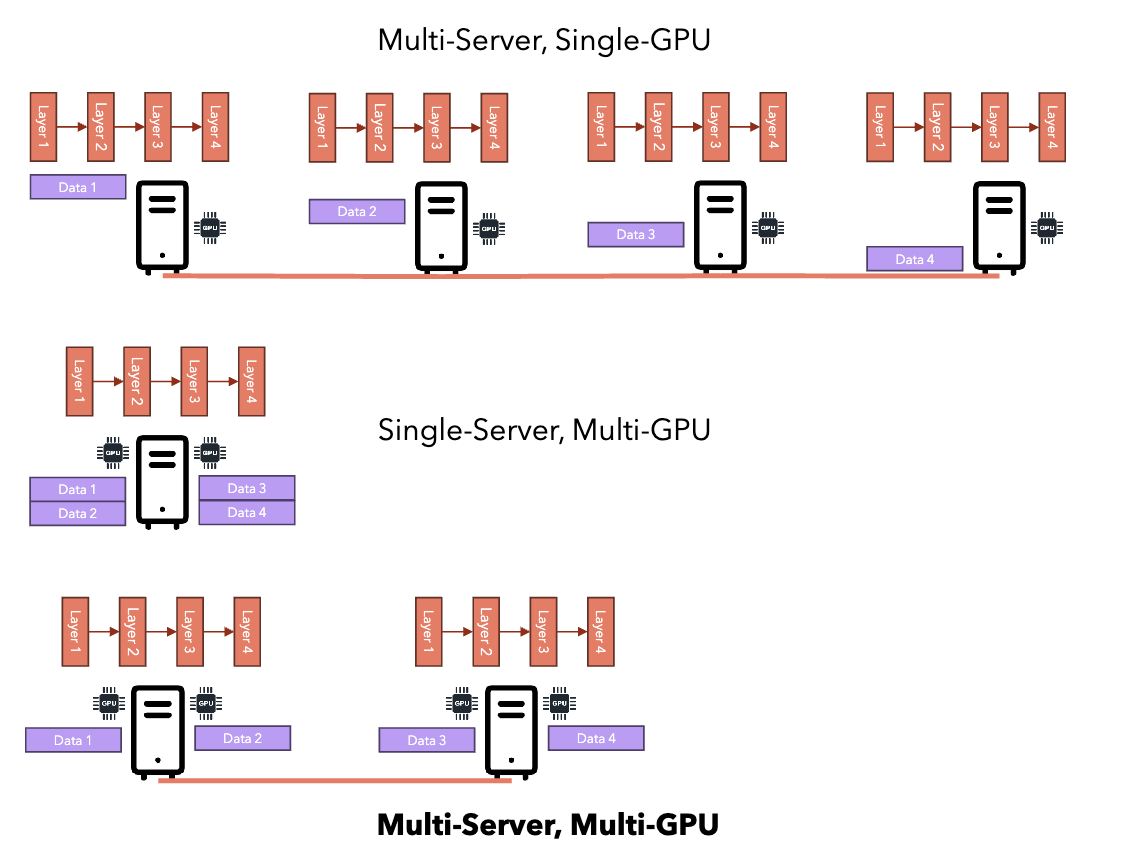
Data Parallelism
- Model fits in a single GPU.
Model Parallelism
- Model too large for single GPU.
DataParallel vs DistributedDataParallel
| Aspect | DataParallel (DP) | DistributedDataParallel (DDP) |
|---|---|---|
| Process Model | Single-process, multi-threaded | Multi-process, typically one process per device (GPU) |
| Machine Support | Only works on a single machine | Supports both single-machine and multi-machine setups |
| Model Replication | Replicated to all devices on every forward pass (high overhead) | Model is replicated once at startup; each process has its own replica |
| Communication | Via threads; master process gathers grads (GIL bottleneck) | Collectives (e.g. all-reduce) run asynchronously outside the GIL |
| Performance | Generally slower due to replication and GIL | Much faster; enables computation/communication overlap |
A process is an independent program with its own memory; a thread is a lightweight unit of work within a process that shares the same memory space with other threads of that process. Processes are isolated, while threads are not.
Distributed Data Parallel (DDP) Workflow
-
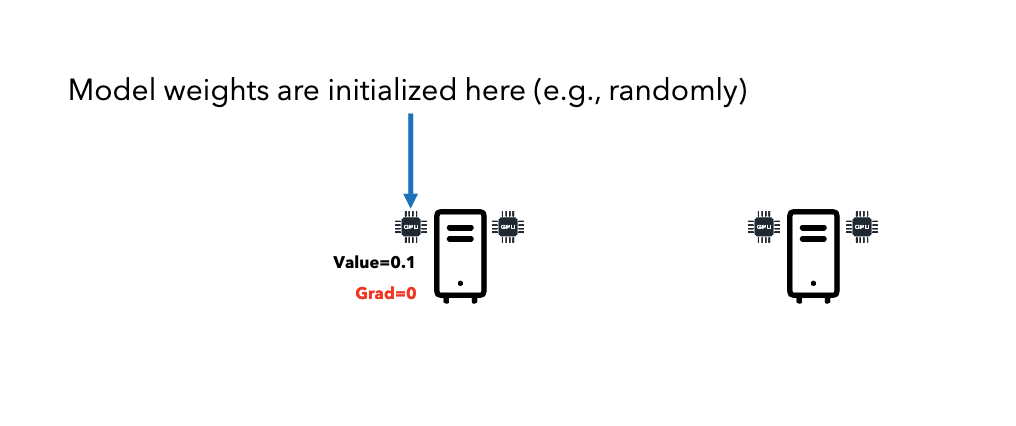
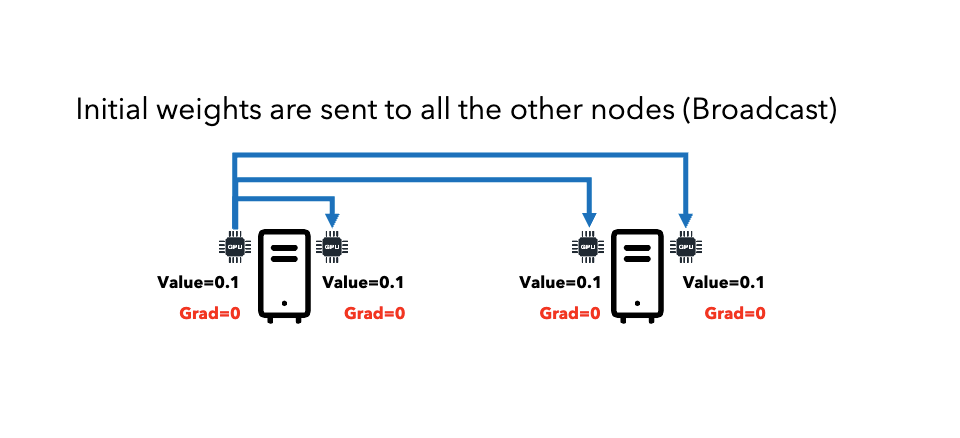
Broadcast: Initialize model weights on one node, send to all nodes.
-
Forward/Backward: Each node trains on different data chunk, computes local gradients.
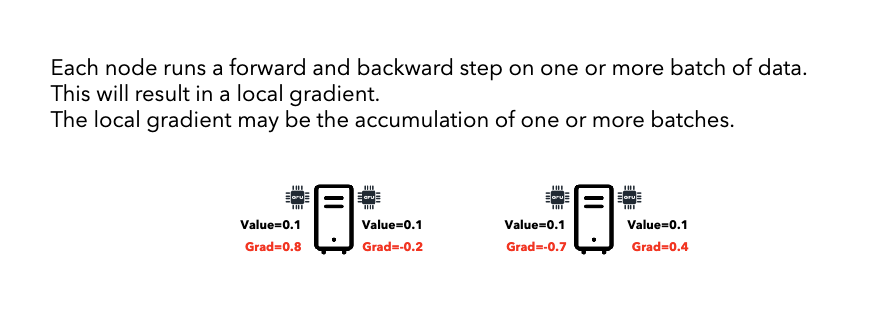
-
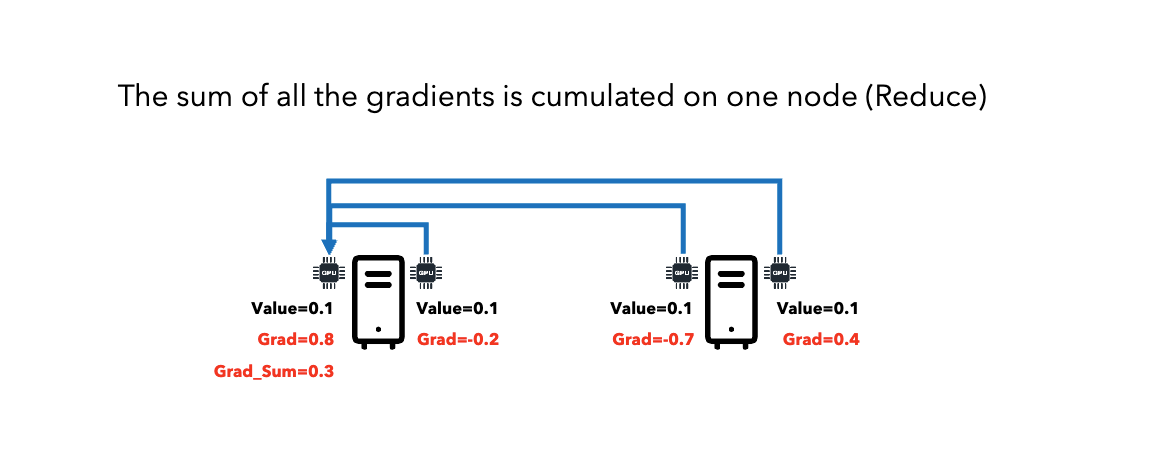
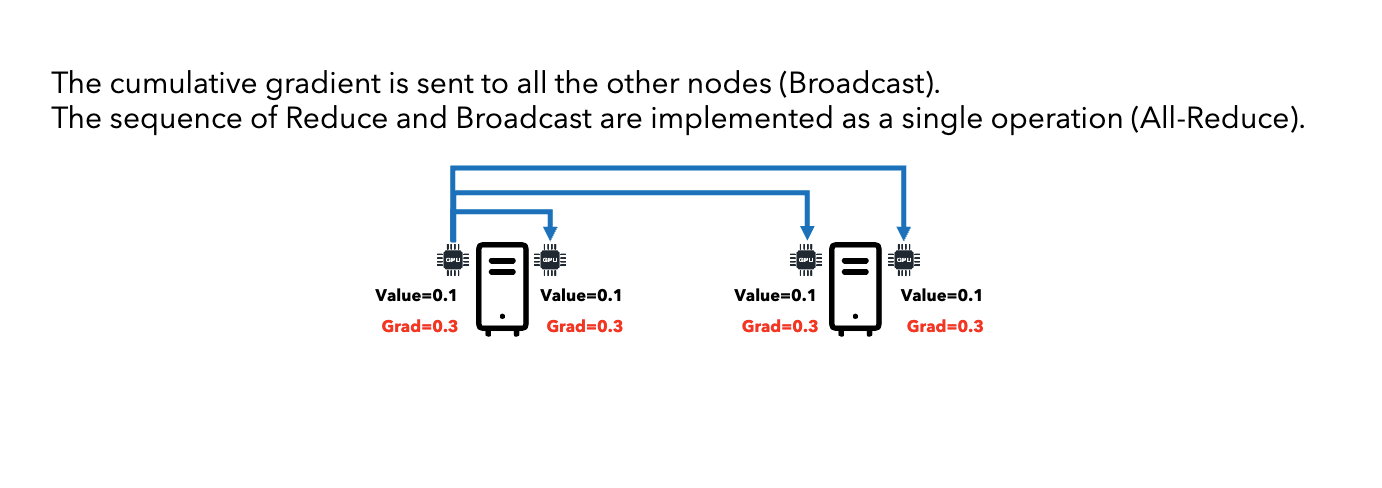
All-Reduce: Sum gradients across all nodes, distribute result to all nodes.
-
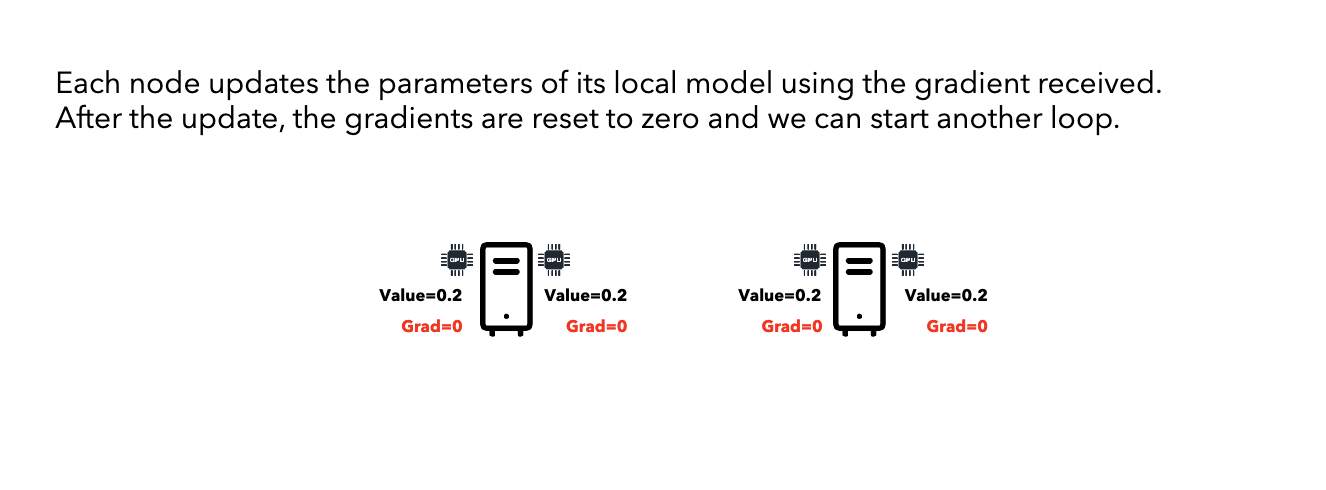
Update: Each node updates its model using the averaged gradients.
Communication Primitives
Reduce (All → One)

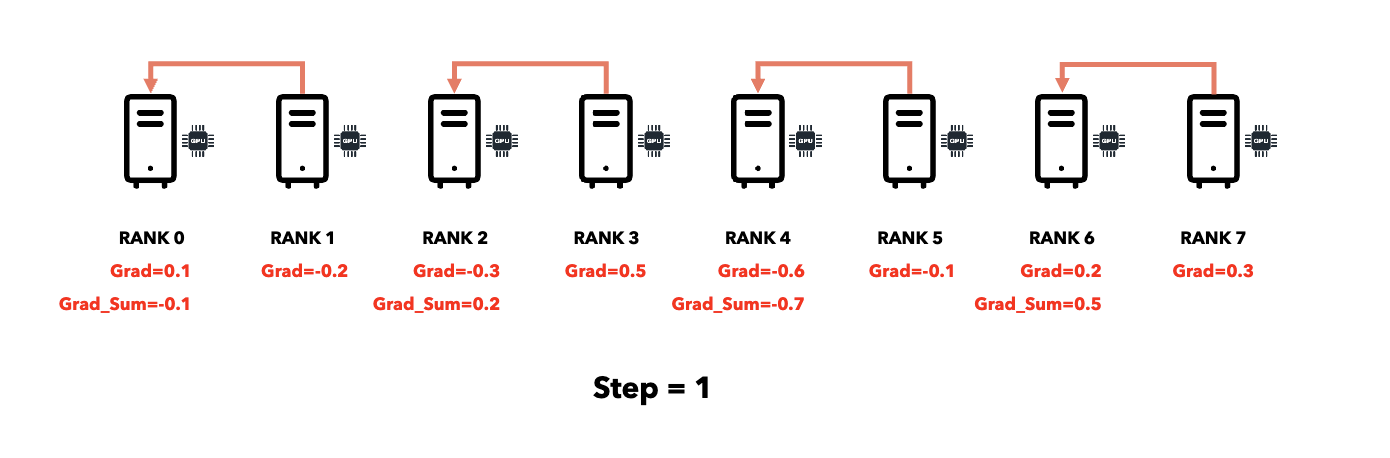
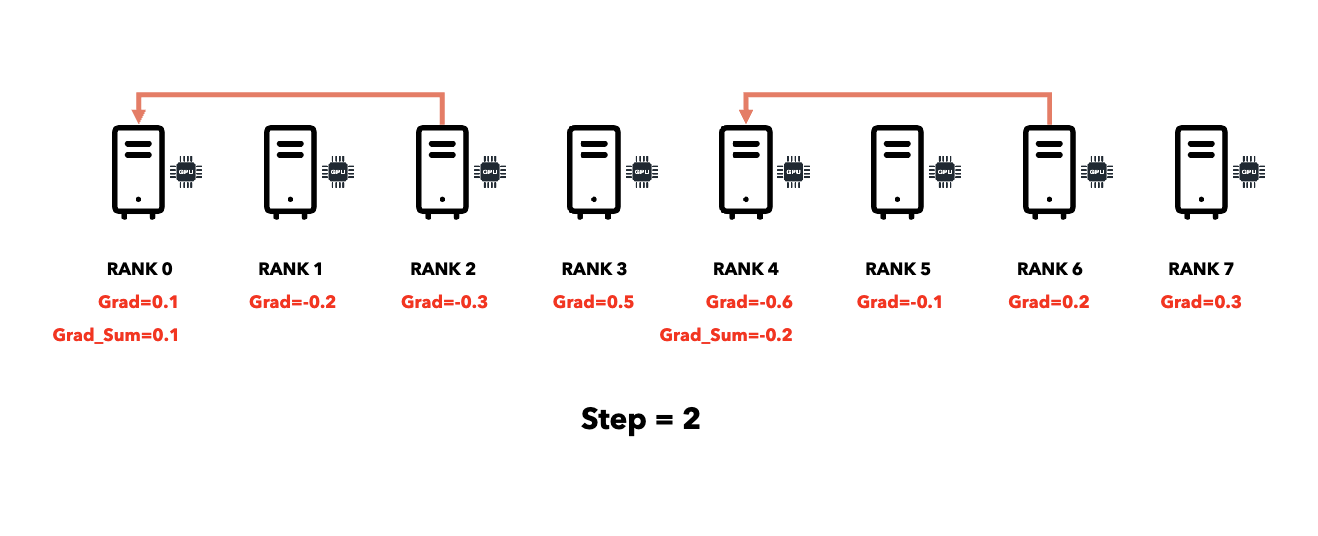
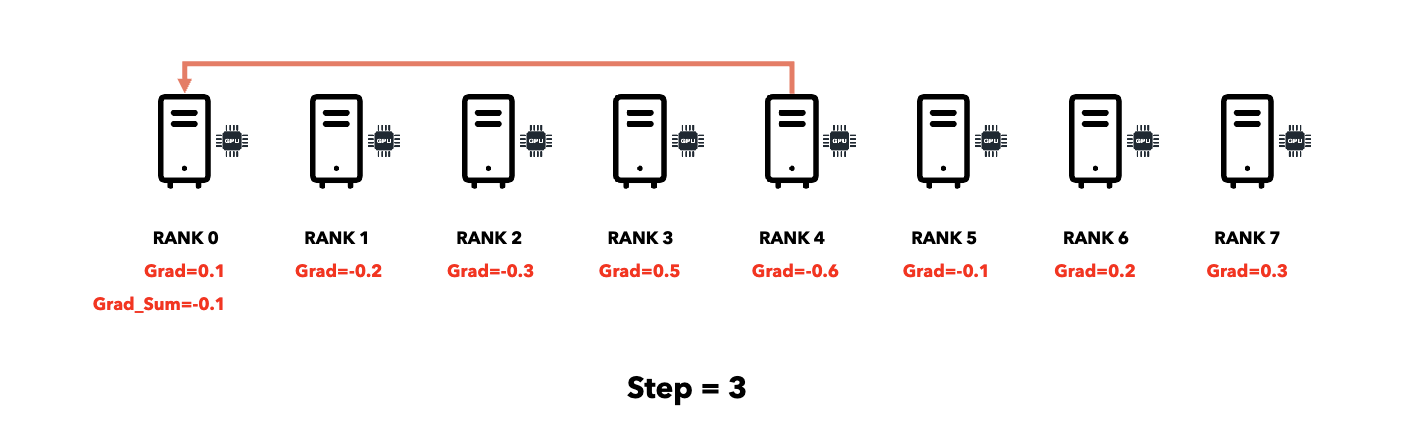
Broadcast (One → All)
Point-to-Point:
- Time: O(n) where n = number of receivers.
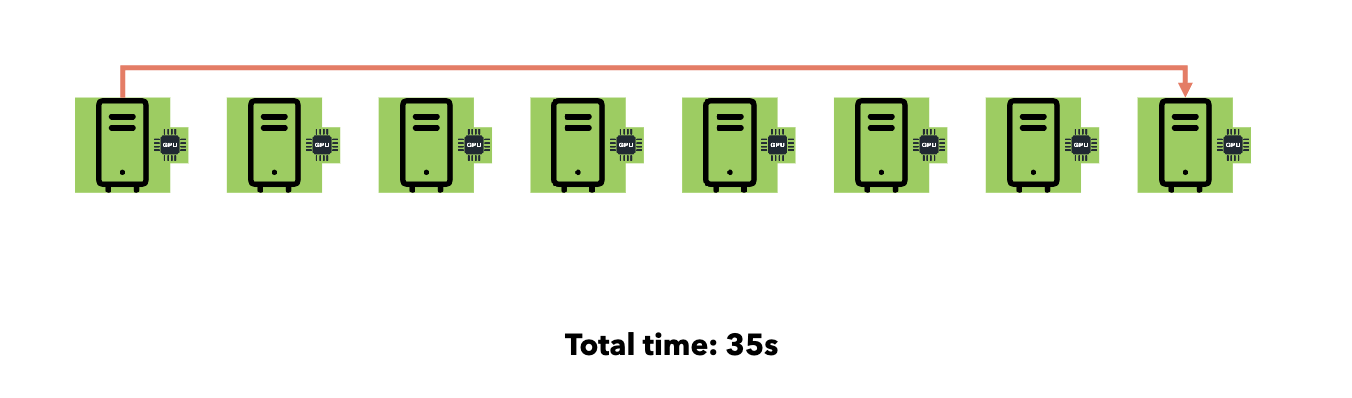
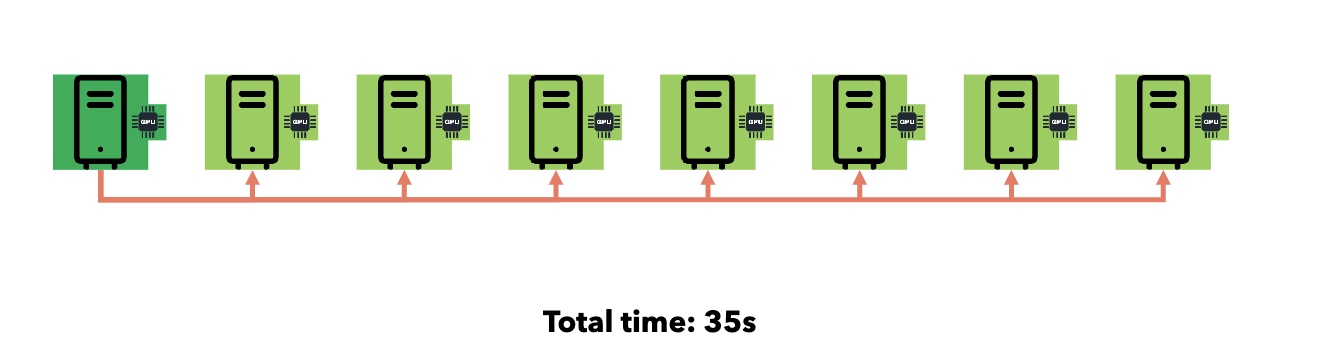
Smart Collective Communication:
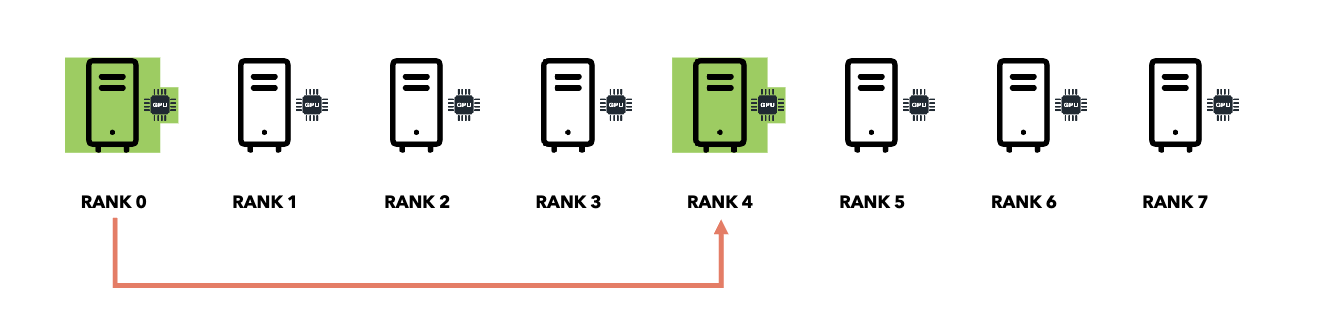
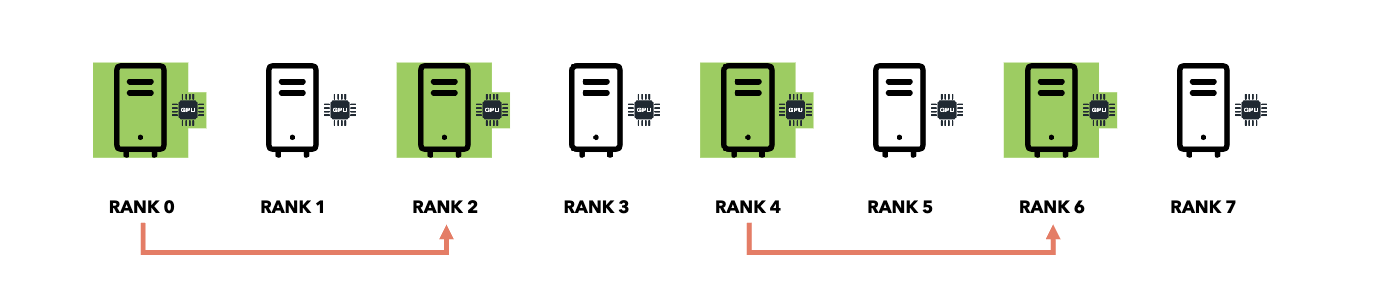
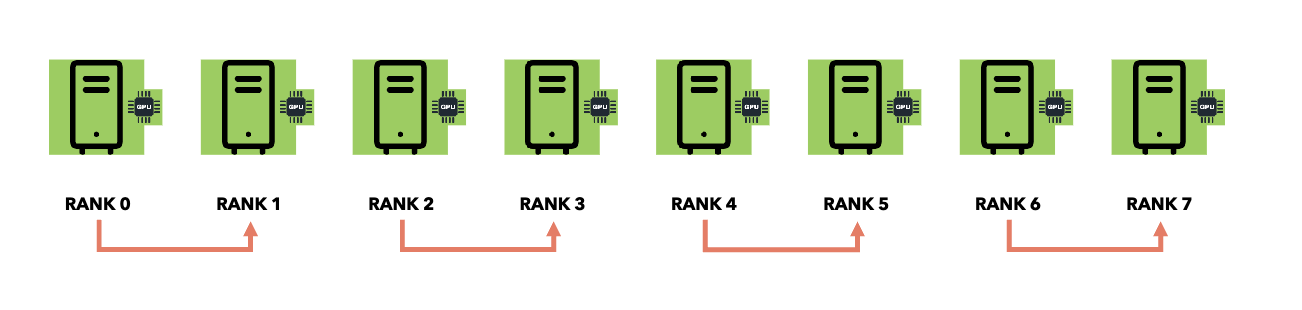
PyTorch DDP Optimizations
Computation-Communication Overlap
- Gradient hooks trigger all-reduce immediately when each gradient is ready.
- Communication overlaps with gradient computation, reducing idle time.
Bucketing
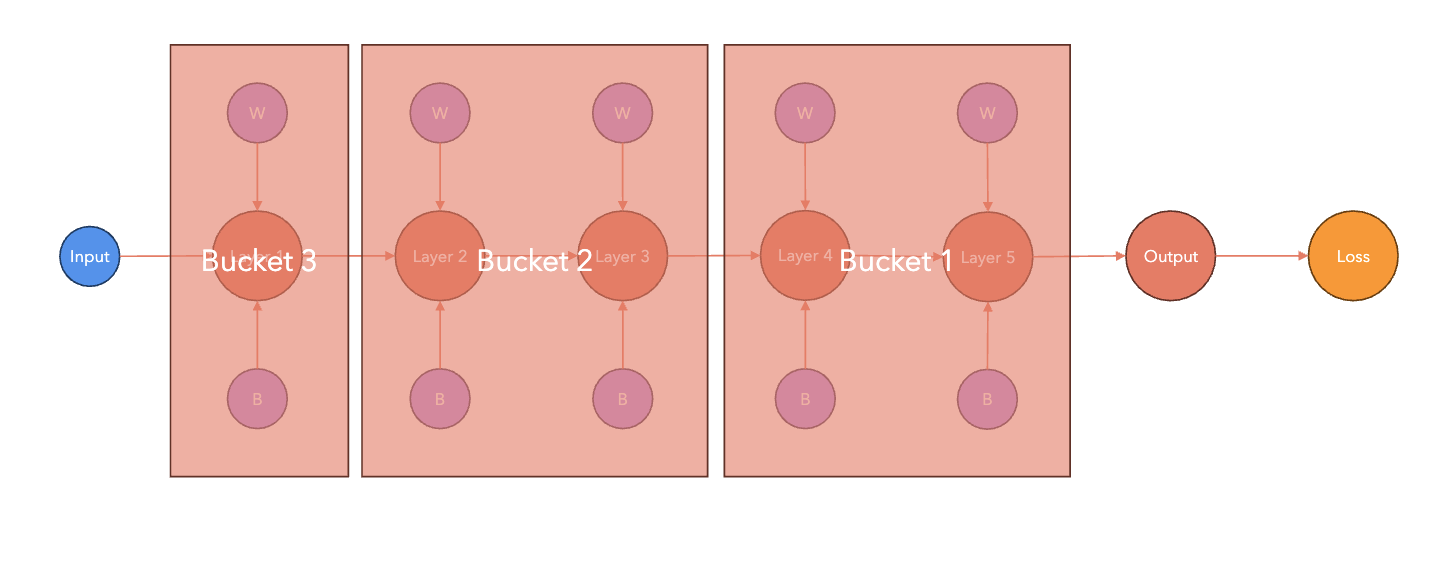
Failover and Checkpointing
- Rank 0 saves model checkpoints as source of truth.