Measuring Chain-of-Thought Determinism in Language Models
Introduction
Chain-of-thought (CoT) reasoning has become a mainstream concept in AI, with models like DeepSeek R1 Llama 8B making their reasoning processes visible. This visibility has sparked interest in understanding the determinism of these reasoning processes. Specifically, are correct CoT paths deterministic while incorrect paths are stochastic? This question is particularly interesting given the recent emergence of CoT models and the potential for low-hanging fruit in interpretability research.
Experimental Setup
I conducted a rigorous black box investigation by intervening manually on the CoT process. The experiment involved:
- Prompting Distilled R1 with formal logic multiple-choice MMLU questions
- Reformating its chain-of-thought reasoning into explicit step-by-step processes using Gemini 2.0 Flash-Lite
- Planting the first reasoning step in every prompt
- Running 10 sample iterations for each question
- Repeating this process for 100 questions
This resulted in a dataset of 100 formal logic questions, each with 10 CoT answers. The analysis focused on accumulating reasoning steps across all questions.
Key Findings
Branching Factor Analysis
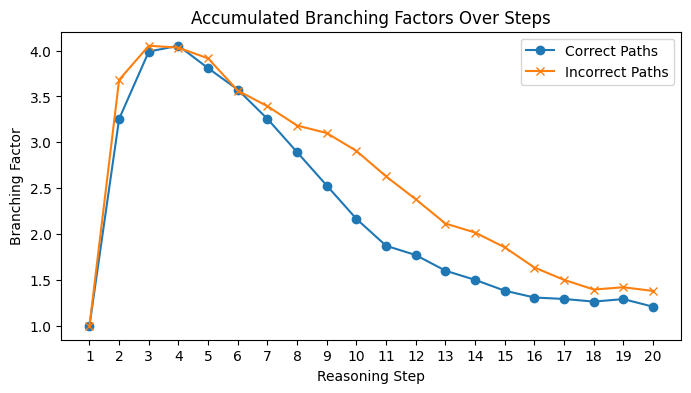
Reasoning paths that yield correct answers tend to have lower branching factors, suggesting more deterministic steps. In contrast, incorrect paths show higher branching, indicating greater uncertainty or divergence. The first step, being manually planted, maintains a branching factor of 1.
Similarity Divergence
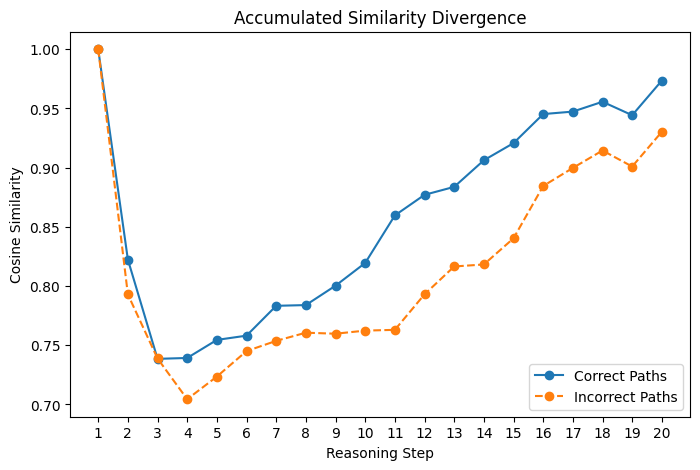
Correct paths maintain higher similarity, suggesting consistency in reasoning. Incorrect paths diverge more, reflecting erratic decision-making. The first step shows perfect similarity since it’s consistently the same. SentenceTransformer was used to embed the reasoning steps in both experiments.
Technical Challenges
The most interesting aspect of this project was learning about model internals to manually plant the first reasoning step. This required understanding special token formatting with <think> and <|Assistant|> tags. Additionally, working within Google Colab’s 15GB VRAM constraint presented challenges, often resulting in the familiar “RuntimeError: CUDA error: out of memory” message.
Future Work
This investigation opens several avenues for future research:
- Exploring the relationship between branching factor and answer correctness
- Investigating the role of model size in CoT determinism
- Developing methods to improve determinism in reasoning processes
- Understanding the impact of different prompting strategies on CoT paths